<tr>
<td>storeEval</td>
<td>var d=new Date(); d.getDate()+'-'+((d.getMonth()+1))
+'-'+d.getFullYear();</td>
<td>date2</td>
</tr>
<tr>
<td>echo</td>
<td>${date2}</td>
<td></td>
</tr>
Monday, December 31, 2012
Rails solved - Capistrano change repository
- Remove deploy/shared/cached-copy
- (remove .ssh/known_hosts) <- optional
- ssh git@xxx.unfuddle.com
- (config.rb add: default_run_options[:pty] = true) <- optional
Known Hosts bug
If you are not using agent forwarding, the first time you deploy may fail due to Capistrano not prompting with this message:
# The authenticity of host 'github.com (207.97.227.239)' can't be established.
# RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48.
# Are you sure you want to continue connecting (yes/no)?
To fix this, ssh into your server as the user you will deploy with, run ssh git@github.com and confirm the prompt.
Sunday, December 30, 2012
Git tips - search a string on all revisions
git rev-list --all | (
while read revision; do
git grep -F 'Your search string' $revision
done
)
Friday, December 28, 2012
Tuesday, December 25, 2012
Cloud server vs VPS
http://forums.eukhost.com/f45/cloud-server-vs-vps-virtual-private-server-11356/#.UNkQBpNevKw
2010
Cloud hosting offers many advantages over normal VPS or Semi-Dedicated server hosting services due to the number of servers that are being used for a single cluster, and if you or your business rely greatly on your website, Cloud hosting is the best suitable option for you. The enhanced architecture powering Cloud hosting solution utilize groups of high specification servers, network attached storage devices to reliably serve every web page, and image of a website. Inside each storage device, drives are replicated to each other in a RAID configuration to create a first level of redundancy.
With Virtual Private server, you will not get guaranteed resources that you will pay for, which means other user of the VPS node could squeeze in on your allotted resources but this is not case with Cloud server, you will get the guaranteed amount of resources you are paying for and it's always available when you need them. In addition to all these features, you will also get the ability to customize the resources of Cloud server anytime. VPS is not at all reliable when compared to Cloud server because VPS is based on software virtualization platform. Each platform of servers have their merits and demerits but here there are no demerits of Cloud server, so now it depends on you whether to choose VPS or Cloud server after understanding the needs and the service that you are looking.
http://www.vps.net/blog/2012/08/20/vps-vs-cloud-server/
Cloud Servers have three primary advantages over a traditional VPS.
Near limitless flexibility with resource sizes.
On the fly resource upgrades, sometimes without even requiring a reboot.
Significantly better redundancy
Centralized redundant storage
2010
Cloud hosting offers many advantages over normal VPS or Semi-Dedicated server hosting services due to the number of servers that are being used for a single cluster, and if you or your business rely greatly on your website, Cloud hosting is the best suitable option for you. The enhanced architecture powering Cloud hosting solution utilize groups of high specification servers, network attached storage devices to reliably serve every web page, and image of a website. Inside each storage device, drives are replicated to each other in a RAID configuration to create a first level of redundancy.
With Virtual Private server, you will not get guaranteed resources that you will pay for, which means other user of the VPS node could squeeze in on your allotted resources but this is not case with Cloud server, you will get the guaranteed amount of resources you are paying for and it's always available when you need them. In addition to all these features, you will also get the ability to customize the resources of Cloud server anytime. VPS is not at all reliable when compared to Cloud server because VPS is based on software virtualization platform. Each platform of servers have their merits and demerits but here there are no demerits of Cloud server, so now it depends on you whether to choose VPS or Cloud server after understanding the needs and the service that you are looking.
http://www.vps.net/blog/2012/08/20/vps-vs-cloud-server/
Cloud Servers have three primary advantages over a traditional VPS.
Near limitless flexibility with resource sizes.
On the fly resource upgrades, sometimes without even requiring a reboot.
Significantly better redundancy
Centralized redundant storage
VPS - not quite reliable on stability
Today, our web hosting on VPS is down. Called the technical support for
the reason saying that VPS down is common.
the reason saying that VPS down is common.
Mac shortcut symbols
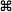 | Command/Apple Key (like Control on a PC) Also written as Cmd |
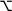 | Option (like Alt on a PC) |
 | Shift |
 | Control (Control-click = Right-click) |
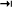 | Tab |
 | Return |
 | Enter (on Number Pad) |
 | Eject |
 | Escape |
 | Page Up |
 | Page Down |
 | Home |
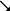 | End |
 | Arrow Keys |
 | Delete Left (like Backspace on a PC) |
 | Delete Right (also called Forward Delete) |
Monday, December 24, 2012
Ruby - Notes on using Yardoc
List Options
$> yard help doc
Add additional tags:
>$ yardoc --tag data_source:"Data Source"
where data_source is the tag in comment. e.g. # @datasource The data is gathered by client collection.
"Data Source" is the string that appears on the generated document.
OR
Create a .yardopts file in project root, add the line --tag data_source:"Data Source"
Then >$yardoc
https://rubydoc.tenderapp.com/kb/getting-started-with-rubydocinfo/setting-up-a-yardopts-file
$> yard help doc
Add additional tags:
>$ yardoc --tag data_source:"Data Source"
where data_source is the tag in comment. e.g. # @datasource The data is gathered by client collection.
"Data Source" is the string that appears on the generated document.
OR
Create a .yardopts file in project root, add the line --tag data_source:"Data Source"
Then >$yardoc
https://rubydoc.tenderapp.com/kb/getting-started-with-rubydocinfo/setting-up-a-yardopts-file
Thursday, December 20, 2012
Ruby yardoc - Remove view source from generated document
1. Create a file like
.../your_project_directory/doc/my_template/default/method_details/setup.rb
2. $>yardoc -p ./doc/my_template
.../your_project_directory/doc/my_template/default/method_details/setup.rb
2. $>yardoc -p ./doc/my_template
Ruby on Rails documentation
YARD
Yay! A Ruby Documentation Tool
http://yardoc.org/
http://rubydoc.info/docs/yard/file/docs/GettingStarted.md
http://rubydoc.info/docs/yard/file/docs/Tags.md#taglist
(rake doc:app hanged on processing one of the class)
Yay! A Ruby Documentation Tool
http://yardoc.org/
http://rubydoc.info/docs/yard/file/docs/GettingStarted.md
http://rubydoc.info/docs/yard/file/docs/Tags.md#taglist
(rake doc:app hanged on processing one of the class)
Rails Solve : You have already activated ... , but your Gemfile requires ...
Solution 1:
Use gems version as in Gemfile.lock $> bundle exec ...
Solution 2:
1. Include e.g. gem "rake", [some_version] in Gemfile
2. Update Gemfile.lock by $> bundle update
Use gems version as in Gemfile.lock $> bundle exec ...
Solution 2:
1. Include e.g. gem "rake", [some_version] in Gemfile
2. Update Gemfile.lock by $> bundle update
Wednesday, December 19, 2012
Visio alternative on Mac
OminGraffle
http://www.omnigroup.com/products/omnigraffle/
And awesome stencils
http://www.graffletopia.com/
Very nice!
See also: draw.io
http://www.omnigroup.com/products/omnigraffle/
And awesome stencils
http://www.graffletopia.com/
Very nice!
See also: draw.io
Mistake - Fix lost after deployment
In today's deployment, one of our previous adhoc fix was lost since I miss the merge from fix to development branch. In order to avoid that from happening again, I will try to use a different branching approach:
Named development branches
This are development branches use for implementation of different features. It can only contain code on story and merge from _production branch. In this way, individual story can be deployed to production without including other stories.
master branch
This is the branch that merge named development branches for the features that's going to be release to staging/production server. It can contains codes from all dev branches and _production branch.
_staging branch
This is the branch in sync with staging release, every deployment to staging server mush be on this branch. Merges from master, dev and/or _production branches for deployment.
_production branch
This is the branch in sync with production release, every deployment to production server must be on this branch. Merges from _staging branch for deployment. Any urgent or adhoc fixes on production branches should be merged to at least master and _staging branch according.
Named development branches
This are development branches use for implementation of different features. It can only contain code on story and merge from _production branch. In this way, individual story can be deployed to production without including other stories.
master branch
This is the branch that merge named development branches for the features that's going to be release to staging/production server. It can contains codes from all dev branches and _production branch.
_staging branch
This is the branch in sync with staging release, every deployment to staging server mush be on this branch. Merges from master, dev and/or _production branches for deployment.
_production branch
This is the branch in sync with production release, every deployment to production server must be on this branch. Merges from _staging branch for deployment. Any urgent or adhoc fixes on production branches should be merged to at least master and _staging branch according.
Monday, December 17, 2012
Thursday, December 13, 2012
Coding convention as on ruby on rails development
As suggested by ruby on rails framework development:
Follow the Coding Conventions
Rails follows a simple set of coding style conventions.
Follow the Coding Conventions
Rails follows a simple set of coding style conventions.
- Two spaces, no tabs (for indentation).
- No trailing whitespace. Blank lines should not have any spaces.
- Indent after private/protected.
- Prefer &&/|| over and/or.
- Prefer class << self over self.method for class methods.
- Use MyClass.my_method(my_arg) not my_method( my_arg ) or my_method my_arg.
- Use a = b and not a=b.
- Follow the conventions in the source you see used already.
- The above are guidelines — please use your best judgment in using them.
Sunday, December 9, 2012
Solve - Modx friendly url not working
Problem:
Modx config -> Friendly URL -> yes.
http://localhost/home.html -> Page not found.
Solution:
enable mod_rewrite:
$> sudo a2enmod rewrite
$> sudo service apache2 restart
/etc/apache2/sites-avaiable/default:
AllowOverride all
ht.access -> .htaccess
Reference:
http://wiki.modxcms.com/index.php/Friendly_URLs_Guide
http://rtfm.modx.com/display/Evo1/Moving+Site
Modx config -> Friendly URL -> yes.
http://localhost/home.html -> Page not found.
Solution:
enable mod_rewrite:
$> sudo a2enmod rewrite
$> sudo service apache2 restart
/etc/apache2/sites-avaiable/default:
AllowOverride all
ht.access -> .htaccess
Reference:
http://wiki.modxcms.com/index.php/Friendly_URLs_Guide
http://rtfm.modx.com/display/Evo1/Moving+Site
Solved - Configuration warning: 'GD and/or Zip PHP extensions not found' on MODX
$ sudo apt-get install php5-gd
reference:
http://www.cyberciti.biz/faq/ubuntu-linux-install-or-add-php-gd-support-to-apache/
reference:
http://www.cyberciti.biz/faq/ubuntu-linux-install-or-add-php-gd-support-to-apache/
Friday, December 7, 2012
Apache add virtual host on a new port
1. Create a site
$> cp /etc/apache2/sites-available/default /etc/apache2/sites-available/newsite
edit /etc/apache2/sites-available/newsite:
<VirtualHost *:8082>
ServerAdmin ops@example.com
DocumentRoot /home/yourname/www
...
2. Enable a site
$> ln -s /etc/apache2/sites-available/newsite /etc/apache2/site-enabled/newsite
3. Listen to the port
edit /etc/apache2/ports.conf
Listen 80
Listen 8082
NameVirtualHost *:80
NameVirtualHost *:8082
$> cp /etc/apache2/sites-available/default /etc/apache2/sites-available/newsite
edit /etc/apache2/sites-available/newsite:
<VirtualHost *:8082>
ServerAdmin ops@example.com
DocumentRoot /home/yourname/www
...
2. Enable a site
$> ln -s /etc/apache2/sites-available/newsite /etc/apache2/site-enabled/newsite
or
$> sudo a2ensite newsite
3. Listen to the port
edit /etc/apache2/ports.conf
Listen 80
Listen 8082
NameVirtualHost *:80
NameVirtualHost *:8082
Thursday, December 6, 2012
Setup Ubuntu for Modx Evolution - Part 3
http://wiki.modxcms.com/index.php/Installation_Guide
Ensure https supports:
sudo a2ensite default-ssl
sudo a2enmod ssl
Note: if site copied from original, make sure it's hosted on the same /home/cms/public_html or change paths accordingly.
Ensure https supports:
sudo a2ensite default-ssl
sudo a2enmod ssl
Note: if site copied from original, make sure it's hosted on the same /home/cms/public_html or change paths accordingly.
Switch to utf8 in mysql on ubuntu - Update
[mysqld]
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_general_ci
[mysqld] default-character-set=utf8 (This line bugged and mysqld couldn't start!) [client] default-character-set=utf8
https://bugs.launchpad.net/ubuntu/+source/mysql-5.5/+bug/958120
Restart:
$> sudo service mysql restart
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_general_ci
[mysqld] default-character-set=utf8 (This line bugged and mysqld couldn't start!) [client] default-character-set=utf8
https://bugs.launchpad.net/ubuntu/+source/mysql-5.5/+bug/958120
Restart:
$> sudo service mysql restart
Switch to utf8 in mysql on ubuntu
http://blog.lesc.se/2011/06/switch-to-utf-8-charset-in-mysql-on.html
Switch to UTF-8 charset in Mysql on Ubuntu
When installing Mysql on Ubuntu the default character set is probably latin-1. Since Ubuntu uses UTF-8 for most other things this may be little strange. But it is easy to change.
The Mysql configuration file
This will make it include settings on the subdirectory
Create a new file:
Restart mysql and you will have UTF-8 as character set:
The Mysql configuration file
/etc/mysql/my.cnf has a magic line:!includedir /etc/mysql/conf.d/
This will make it include settings on the subdirectory
conf.d. It's not recommended to change the my.cnffile directly since it will cause problems when upgrading Ubuntu/Mysql to a new version.Create a new file:
/etc/mysql/conf.d/utf8_charset.cnf with the following contents:[mysqld] default-character-set=utf8 [client] default-character-set=utf8
Restart mysql and you will have UTF-8 as character set:
$ mysql -u root -p -e "show variables like '%character%'" +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+
Setup Ubuntu for Modx Evolution - Part 2
Configurations:
Create user account:
$> sudo useradd -m -s /bin/bash cms
$> sudo passwd cms
The user created will not be in the sudoers file.
-s : for setting the bash be the default shell.
-m: create /home/cms as user's home directory.
($> sudo userdel -r cms) to rollback
Migrate contents from current Modx CMS hosting on another server.
1. GZip tar and download the entire /public_html directory for old server.
2. Upload to /home/cms.
3. $> tar -zxvf public_html.tar.gz
4. Set apache document root to /home/cms/public_html
5. Restart apache: sudo service apache2 restart
6. Locate database config file: search database name within the files under /public_html
7. Config file: /manager/includes/config.inc.php
8. On the old server, export database by phpmyadmin>Export databases. -> localhost.sql
9. Copy localhost.sql to /home/cms
10. Restore database: $> mysql - u user_name -p database_name < file_name.sql
Create user account:
$> sudo useradd -m -s /bin/bash cms
$> sudo passwd cms
The user created will not be in the sudoers file.
-s : for setting the bash be the default shell.
-m: create /home/cms as user's home directory.
($> sudo userdel -r cms) to rollback
Migrate contents from current Modx CMS hosting on another server.
1. GZip tar and download the entire /public_html directory for old server.
2. Upload to /home/cms.
3. $> tar -zxvf public_html.tar.gz
4. Set apache document root to /home/cms/public_html
5. Restart apache: sudo service apache2 restart
6. Locate database config file: search database name within the files under /public_html
7. Config file: /manager/includes/config.inc.php
8. On the old server, export database by phpmyadmin>Export databases. -> localhost.sql
9. Copy localhost.sql to /home/cms
10. Restore database: $> mysql - u user_name -p database_name < file_name.sql
References:
http://www.cyberciti.biz/faq/howto-add-new-linux-user-account/
http://linux.vbird.org/linux_basic/0410accountmanager.php
http://www.howtogeek.com/howto/ubuntu/add-a-user-on-ubuntu-server/
http://codeistry.com/help/uploading-downloading-and-backing-up-modx-sites
http://www.cyberciti.biz/faq/howto-add-new-linux-user-account/
http://linux.vbird.org/linux_basic/0410accountmanager.php
http://www.howtogeek.com/howto/ubuntu/add-a-user-on-ubuntu-server/
http://codeistry.com/help/uploading-downloading-and-backing-up-modx-sites
Project management - decide a story's point on task board
When it comes to review stories on task board and have to decide the
complexity points on every story, one approach is for every developer
and lead to think on their own without communicate with each other.
Then after everyone is ready, show the estimated points to all and
discuss the reason behind it. It would be quite a effective way.
complexity points on every story, one approach is for every developer
and lead to think on their own without communicate with each other.
Then after everyone is ready, show the estimated points to all and
discuss the reason behind it. It would be quite a effective way.
Wednesday, December 5, 2012
Setup Ubuntu for Modx Evolution - Part 1
Procedures for setup Ubuntu and Modx Revolution:
Install Ubuntu Server 12.04
SSH:
Installation: sudo apt-get install openssh-server openssh-client
Verify: ssh localhost
Apache2:
Installation: sudo apt-get install apache2
Verify: http://localhost or the IP
Verify: sudo netstat -tap | grep mysql
Location: /etc/apache2/
Mysql:
Installation:
sudo apt-get install mysql-server
sudo apt-get install php5-mysql
Verify: sudo netstat -tap | grep mysql
PHP5:
Installation: sudo apt-get install php5 libapache2-mod-php5
Restart Apache: sudo service apache2 restart
Verify: <?php
phpinfo();
?>
Configurations:
edit /etc/apache2/sites-available/default, set the DocumentRoot there to /home/your_name/www
References:
http://www.cyberciti.biz/faq/ubuntu-linux-openssh-server-installation-and-configuration/
https://help.ubuntu.com/12.04/serverguide/index.html
Install Ubuntu Server 12.04
SSH:
Installation: sudo apt-get install openssh-server openssh-client
Verify: ssh localhost
Apache2:
Installation: sudo apt-get install apache2
Verify: http://localhost or the IP
Verify: sudo netstat -tap | grep mysql
Location: /etc/apache2/
Mysql:
Installation:
sudo apt-get install mysql-server
sudo apt-get install php5-mysql
Verify: sudo netstat -tap | grep mysql
PHP5:
Installation: sudo apt-get install php5 libapache2-mod-php5
Restart Apache: sudo service apache2 restart
Verify: <?php
phpinfo();
?>
Configurations:
edit /etc/apache2/sites-available/default, set the DocumentRoot there to /home/your_name/www
References:
http://www.cyberciti.biz/faq/ubuntu-linux-openssh-server-installation-and-configuration/
https://help.ubuntu.com/12.04/serverguide/index.html
postgresql psql show database, table, column
SHOW TABLE:
postgresql: \d
postgresql: SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
SHOW DATABASES
postgresql: \l
postgresql: SELECT datname FROM pg_database;
SHOW COLUMNS
postgresql: \d table
postgresql: SELECT column_name FROM information_schema.columns WHERE table_name ='table';
DESCRIBE TABLE
postgresql: \d+ table
postgresql: SELECT column_name FROM information_schema.columns WHERE table_name ='table';
RENAME DATABASE
postgresql: alter database old_name rename to new_name;
postgresql: \d
postgresql: SELECT table_name FROM information_schema.tables WHERE table_schema = 'public';
SHOW DATABASES
postgresql: \l
postgresql: SELECT datname FROM pg_database;
SHOW COLUMNS
postgresql: \d table
postgresql: SELECT column_name FROM information_schema.columns WHERE table_name ='table';
DESCRIBE TABLE
postgresql: \d+ table
postgresql: SELECT column_name FROM information_schema.columns WHERE table_name ='table';
RENAME DATABASE
postgresql: alter database old_name rename to new_name;
Monday, December 3, 2012
Rails migration by sql statement directly
Sometimes you need to do something in SQL not abstracted directly by migrations:
class MakeJoinUnique < ActiveRecord::Migration
def up
execute "ALTER TABLE `pages_linked_pages` ADD UNIQUE `page_id_linked_page_id` (`page_id`,`linked_page_id`)"
end
def down
execute "ALTER TABLE `pages_linked_pages` DROP INDEX `page_id_linked_page_id`"
end
end
Saturday, December 1, 2012
Project - Enhancement on website to provide online application and facebook integration
On this story, we are going to enhance our current company website to support online application. Within the application, we will correct client's personal information together with their Facebook authentication for further user information collection.
Requirements:
Requirements:
- Online application in a secured channel.
- Uploaded application and attached document needs to be secured.
- Collect Facebook authentication token.
- Access to submitted application from our internal staff in secure way.
- The current website was design and created by a website design house. Mainly static contents.
- We have an internal system which stores all client's sensitive information.
- We have register company domain and website is hosting on a shared hosting plan. i.e. Many other outside domains are hosted together, sharing resources and IP. This was fine at the moment since we only serves static information on our website.
- Website contents is managed by Modx.
- Design house will be responsible for creating new application form on our website.
- We will setup the environment for new website deployment and make sure the security of application data.
- Since our online application need to be secured, we needs https on application pages.
- Internal system should be separated from website for security concerns.
- Application data will be stored on hosting server database and file system.
- The application data on website should only be a temporary storage. Once it's retrieved from our staff, it should be cleanup from website database.
- Application data should not be accessible by Design house personnel. We should only provide minimal access for their deployment. Once done, we should restrict their access.
- Access to application data on website should be granted only to IPs from office and internal system servers.
- Move web hosting to VPS so as to get a dedicated IP and server resource.
- Setup VPS and grant required access to design house for their deployment.
- Create access point on getting the Facebook authentication token and applications into our internal system.
- The original communication between us and design house was handle by another colleague who didn't say anything about online application security concerns. No HTTPS was plan in the implementation.
- Raise security concern to product director.
- Agreed on we should make all application form secured. Using HTTPS and SSL connections.
- Secure points: submission of form; Storage of application data on web server; Secure retrieval of data from web server to our internal system.
- Coordinate with design house to make sure we are on the same picture and they know what they're going to do.
- Coordinate with developer on the way to get access Facebook token that will be stored on web site database.
- Apply VPS hosting plan. Pay the bill, get access to VPS.
- Setup VPS for Modx deploy.
- ....
Monday, November 26, 2012
Modx send email
We were having problem on our website to send email to our staffs. The web content is servered by Modx and design and developed by a design house.
After looking into the code, it's found that the default email server was not able to send email to our gmail domain email address. To server the problem, we use another server on sendgrid.
$mail = new PHPMailer();
$mail->From = 'xxx@xxx-xxx.com';
$mail->FromName = 'some name';
$mail->IsSMTP();
$mail->Host = "www.sendgrid.net";
$mail->Port = 3535;
$mail->SMTPDebug = 1;
$mail->SMTPAuth = true;
...
After looking into the code, it's found that the default email server was not able to send email to our gmail domain email address. To server the problem, we use another server on sendgrid.
$mail = new PHPMailer();
$mail->From = 'xxx@xxx-xxx.com';
$mail->FromName = 'some name';
$mail->IsSMTP();
$mail->Host = "www.sendgrid.net";
$mail->Port = 3535;
$mail->SMTPDebug = 1;
$mail->SMTPAuth = true;
...
Wednesday, November 21, 2012
Tuesday, November 20, 2012

Thursday, November 15, 2012
Wednesday, November 14, 2012
Rails - Rails console useful tips
[8] pry(main)> app.class
=> ActionDispatch::Integration::Session
[9] pry(main)> app.users_path
=> "/users"
[10] pry(main)> app.root_url
=> "http://www.example.com/"
[11] pry(main)> app.new_user_session_path
=> "/user/sign_in"
[14] pry(main)> app.get '/users'
=> 302
[15] pry(main)> app.response.body.length
=> 101
app.get
app.post
app.put
app.delete
[13] pry(main)> helper.class
=> ActionView::Base
[17] pry(main)> "".methods.grep(/case/).sort
=> ["camelcase",
"casecmp",
"downcase",
"downcase!",
"swapcase",
"swapcase!",
"titlecase",
"upcase",
"upcase!"]
[18] pry(main)> all_users = User.all; nil
User Load (1.6ms) SELECT "users".* FROM "users"
=> nil
[22] pry(main)> y User.first
User Load (1.0ms) SELECT "users".* FROM "users" LIMIT 1
--- !ruby/ActiveRecord:User
attributes:
name: ghealey
encrypted_password: $2a$10$rhYT.gbYbOanyudJa19cluQ1XlFFh4ntC8IhH5p.xxa9ddrtSx4.O
created_at: 2010-11-26 05:51:01.32897
failed_attempts: "0"
updated_at: 2012-11-14 06:20:53.496916
last_sign_in_ip:
email: ghealey@example.com
=> nil
References:
http://37signals.com/svn/posts/3176-three-quick-rails-console-tips
http://samuelmullen.com/2012/07/getting-more-out-of-the-rails-console/
http://paulsturgess.co.uk/articles/39-debugging-tips-in-ruby-on-rails
http://www.therailworld.com/posts/35-Interacting-with-Controllers-via-the-app-object
=> ActionDispatch::Integration::Session
[9] pry(main)> app.users_path
=> "/users"
[10] pry(main)> app.root_url
=> "http://www.example.com/"
[11] pry(main)> app.new_user_session_path
=> "/user/sign_in"
[14] pry(main)> app.get '/users'
=> 302
[15] pry(main)> app.response.body.length
=> 101
app.get
app.post
app.put
app.delete
[13] pry(main)> helper.class
=> ActionView::Base
[17] pry(main)> "".methods.grep(/case/).sort
=> ["camelcase",
"casecmp",
"downcase",
"downcase!",
"swapcase",
"swapcase!",
"titlecase",
"upcase",
"upcase!"]
[18] pry(main)> all_users = User.all; nil
User Load (1.6ms) SELECT "users".* FROM "users"
=> nil
[22] pry(main)> y User.first
User Load (1.0ms) SELECT "users".* FROM "users" LIMIT 1
--- !ruby/ActiveRecord:User
attributes:
name: ghealey
encrypted_password: $2a$10$rhYT.gbYbOanyudJa19cluQ1XlFFh4ntC8IhH5p.xxa9ddrtSx4.O
created_at: 2010-11-26 05:51:01.32897
failed_attempts: "0"
updated_at: 2012-11-14 06:20:53.496916
last_sign_in_ip:
email: ghealey@example.com
=> nil
References:
http://37signals.com/svn/posts/3176-three-quick-rails-console-tips
http://samuelmullen.com/2012/07/getting-more-out-of-the-rails-console/
http://paulsturgess.co.uk/articles/39-debugging-tips-in-ruby-on-rails
http://www.therailworld.com/posts/35-Interacting-with-Controllers-via-the-app-object
Gmail alias
http://support.google.com/mail/bin/answer.py?hl=en&answer=12096
Gmail doesn't offer traditional aliases, but you can receive messages sent to your.username+any.alias@gmail.com. For example, messages sent to jane.doe+notes@gmail.com are delivered to jane.doe@gmail.com.
Gmail doesn't offer traditional aliases, but you can receive messages sent to your.username+any.alias@gmail.com. For example, messages sent to jane.doe+notes@gmail.com are delivered to jane.doe@gmail.com.
Tuesday, November 13, 2012
Jenkins, Rails - Run rails test directly on Jenkins workspace
$ cd /var/lib/jenkins/jobs/[Jenkins_project_name]/workspace/
$ RAILS_ENV=test bundle exec rake test:units
$ RAILS_ENV=test bundle exec rake test:units
Rails - Trace and solve rake db migration error
We were doing a simple db migration in which a new column, say 'valuation_date', is added to an existing model 'Record'. In the migration, the valuation_date column is added. Then a code segment is executed to assign value to it. Like this:
def self.up
add_column :records, :valuation_date, :date
Record.find_each do |record|
record.valuation_date = ...
record.save
end
end
The deployment (rake db:migrate) works fine on development environment. However, when doing cap deploy:migrations, it returns error:
== AddValutionDateToRecords: migrating ===================================
-- add_column(:records, :valuation_date, :date)
-> 0.0014s
rake aborted!
An error has occurred, this and all later migrations canceled:
undefined method `column' for nil:NilClass
Tasks: TOP => db:migrate
(See full trace by running task with --trace)
Turns out this only happens when running the migration under rails' staging environment. Then tried execute the db migration and trace the issue.
$ bundle exec rake RAILS_ENV=staging db:migrate --trace
undefined method `relation' for nil:NilClass
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/arel-2.0.10/lib/arel/crud.rb:12:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/persistence.rb:266:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/locking/optimistic.rb:77:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/attribute_methods/dirty.rb:68:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/timestamp.rb:60:in `update'
...
To look deeper, set a "debugger" breakpoint before record.save. Then another 2 breakpoints on crud.rb:12 .../active_record/base.rb:1718. It was found that record.class.arel_table['valuation_date'] is nil that caused the failure.
Investigation #1
Check if the Arel using different version in different environments. In debug mode, $ p Arel::VERSION show they are the same.
Investigation #2
Compare the difference between dev and staging:
$ rake about
$ rake RAILS_ENV=staging about
The results show that ActionDispatch::Static middleware is not include in staging. Tried to comment out the config.serve_static_asserts = false in config/environments/production.rb. Then the middleware ActionDispatch::Static is added. But it doesn't help.
Investigation #3
Change the settings on config/environments/production.rb to those in config/environments/development.rb one by one to locate what makes the difference. Luckily, the first one hits. It is the config.cache_classes=true on staging environment that leaded to the error. The model column was cached and not reloaded after add_column. So, the assign and save of a record resulted in error. To solve the problem, after add_column, do a reset_column_information. i.e.
def self.up
add_column :records, :valuation_date, :date
Record.reset_column_information
Record.find_each do |record|
record.valuation_date = ...
record.save
end
end
Problem solved!
def self.up
add_column :records, :valuation_date, :date
Record.find_each do |record|
record.valuation_date = ...
record.save
end
end
The deployment (rake db:migrate) works fine on development environment. However, when doing cap deploy:migrations, it returns error:
== AddValutionDateToRecords: migrating ===================================
-- add_column(:records, :valuation_date, :date)
-> 0.0014s
rake aborted!
An error has occurred, this and all later migrations canceled:
undefined method `column' for nil:NilClass
Tasks: TOP => db:migrate
(See full trace by running task with --trace)
Turns out this only happens when running the migration under rails' staging environment. Then tried execute the db migration and trace the issue.
$ bundle exec rake RAILS_ENV=staging db:migrate --trace
undefined method `relation' for nil:NilClass
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/arel-2.0.10/lib/arel/crud.rb:12:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/persistence.rb:266:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/locking/optimistic.rb:77:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/attribute_methods/dirty.rb:68:in `update'
/Users/laileo/.rvm/gems/ree-1.8.7-2011.03@merlot/gems/activerecord-3.0.11/lib/active_record/timestamp.rb:60:in `update'
...
To look deeper, set a "debugger" breakpoint before record.save. Then another 2 breakpoints on crud.rb:12 .../active_record/base.rb:1718. It was found that record.class.arel_table['valuation_date'] is nil that caused the failure.
Investigation #1
Check if the Arel using different version in different environments. In debug mode, $ p Arel::VERSION show they are the same.
Investigation #2
Compare the difference between dev and staging:
$ rake about
$ rake RAILS_ENV=staging about
The results show that ActionDispatch::Static middleware is not include in staging. Tried to comment out the config.serve_static_asserts = false in config/environments/production.rb. Then the middleware ActionDispatch::Static is added. But it doesn't help.
Investigation #3
Change the settings on config/environments/production.rb to those in config/environments/development.rb one by one to locate what makes the difference. Luckily, the first one hits. It is the config.cache_classes=true on staging environment that leaded to the error. The model column was cached and not reloaded after add_column. So, the assign and save of a record resulted in error. To solve the problem, after add_column, do a reset_column_information. i.e.
def self.up
add_column :records, :valuation_date, :date
Record.reset_column_information
Record.find_each do |record|
record.valuation_date = ...
record.save
end
end
Problem solved!
rails - rake about
When "rake" fails on certain RAILS_ENV, check and compare the rake
information by rake about.
$ rake RAILS_ENV=staging about
$ rake about
information by rake about.
$ rake RAILS_ENV=staging about
$ rake about
Rails - A closer look on ActonRecord and ARel
Monday, November 12, 2012
A few notes on selenium IDE usage
- For time consuming actions:
click - some location
waitForPageToLoad
pause
- For page waits for ajax response:
click - ajax button
pause
... next action ...
- Use selenium locator for target:
id=...
css=...
click - some location
waitForPageToLoad
pause
- For page waits for ajax response:
click - ajax button
pause
... next action ...
- Use selenium locator for target:
id=...
css=...
Friday, November 9, 2012
Management practice - Set deadline for every task
No matter which development methodology is using, whether it is Scrum or Kanban, it's a good idea to set a date on which a task should be finished. For Scrum, within a sprint, 2 weeks or 3 weeks, certain PBIs/stories have to be completed. This can push or encourage developers to aim tasks for the deadline. Otherwise, developers may try to refactor and refactor for a better solution or test again and again. There's no perfect solution. Just set a date and let stories be closed on that date. Then start new tasks on next cycle.
Another advantage is to provide a product road map for product owner to foresee and expect certain features to be done on certain milestones.
Another advantage is to provide a product road map for product owner to foresee and expect certain features to be done on certain milestones.
Thursday, November 8, 2012
Selenium IDE - select element by CSS
select element by css:
<tr>
<td>verifyElementPresent</td>
<td>css=span#direct-debit-scheme-menu-title</td>
<td></td>
</tr>
<tr>
<td>verifyElementPresent</td>
<td>css=span#direct-debit-scheme-menu-title</td>
<td></td>
</tr>
Create a bootable USB stick on Mac
references:
http://www.ubuntu.com/download/help/create-a-usb-stick-on-mac-osx
http://renevanbelzen.wordpress.com/2009/10/14/creating-a-bootable-usb-stick-with-mac-os-x-in-10-easy-steps/
$ diskutil list
$ diskutil unmountDisk /dev/diskN (where diskN is the USB drive)
$ mv ...../clonezilla-live-1.2.12-67-amd64.iso ..../clonezilla-live-1.2.12-67-amd64.dmg
$ su
$ dd if=/Users/myself/isoDisks/clonezilla-live-1.2.12-67-amd64.dmg of=/dev/disk5 bs=1m
$ diskutil list
$ diskutil eject /dev/disk5
http://www.ubuntu.com/download/help/create-a-usb-stick-on-mac-osx
http://renevanbelzen.wordpress.com/2009/10/14/creating-a-bootable-usb-stick-with-mac-os-x-in-10-easy-steps/
$ diskutil list
$ diskutil unmountDisk /dev/diskN (where diskN is the USB drive)
$ mv ...../clonezilla-live-1.2.12-67-amd64.iso ..../clonezilla-live-1.2.12-67-amd64.dmg
$ su
$ dd if=/Users/myself/isoDisks/clonezilla-live-1.2.12-67-amd64.dmg of=/dev/disk5 bs=1m
$ diskutil list
$ diskutil eject /dev/disk5
Wednesday, November 7, 2012
Clone hard disk
http://www.techmixer.com/free-clone-hard-disk-software-to-clone-your-hard-disk-data/
Tried Clonezilla, works great!
Tried Clonezilla, works great!
Rescue failed desktop/server/laptop
SystemResuceCD
Keyword: System, Failure, Windows, Linux, Boot, CD
Keyword: System, Failure, Windows, Linux, Boot, CD
Friday, November 2, 2012
Rails note - Builds single purpose controller method/route
Just a simple note:
In Rails application, it would be better for every controller
method/route serves single purpose, instead of multiple purposes and
switch by parameter options.
This approach provides a cleaner view for system maintenance and auditing.
In Rails application, it would be better for every controller
method/route serves single purpose, instead of multiple purposes and
switch by parameter options.
This approach provides a cleaner view for system maintenance and auditing.
SSH tunnel vs VPN in short
Both: Encrypted data for secure connection.
VPN: Operating System level security
SSH: Application level security
VPN: Share intranet resource such as file shares, network printer, etc
SSH: Setup per individual resources.
VPN: Easy for client usage. More to do on server setup.
SSH: Not easy for novice user. Easy for SSH server setup.
VPN: More secure for business use. You can force all network traffic on
system through VPN.
SSH: Good for single purpose connection. e.g. remote access intranet
server.
VPN: Operating System level security
SSH: Application level security
VPN: Share intranet resource such as file shares, network printer, etc
SSH: Setup per individual resources.
VPN: Easy for client usage. More to do on server setup.
SSH: Not easy for novice user. Easy for SSH server setup.
VPN: More secure for business use. You can force all network traffic on
system through VPN.
SSH: Good for single purpose connection. e.g. remote access intranet
server.
Thursday, October 25, 2012
Tuesday, October 23, 2012
Nginx over Apache
" I ran a simple test against Nginx v0.5.22 and Apache v2.2.8 using ab (Apache's benchmarking tool). During the tests, I monitored the system with vmstat and top. The results indicate that Nginx outperforms Apache when serving static content. Both servers performed best with a concurrency of 100. Apache used four worker processes (threaded mode), 30% CPU and 17MB of memory to serve 6,500 requests per second. Nginx used one worker, 15% CPU and 1MB of memory to serve 11,500 requests per second."
-- Linux Journal
-- Linux Journal
Monday, October 22, 2012
Right tools for the right task - Reasons for moving from Node.js to Ruby on Rails
reference:http://www.aqee.net/why-we-moved-from-nodejs-to-ror/
为什么我们要从 NodeJS 迁移到 Ruby on Rails
声明:这篇文章绝不是一篇讨论 NodeJS 和 Ruby on Rails 孰优孰略的檄文。它描述的只是我们做决策过程中的一些思考、决策背后的原因。两种框架都非常优秀,都出色的完成了它们的设计初衷,这也是为什么我们部分的 模块仍然运行在NodeJS上的原因。
我是NodeJs的大粉丝,认为这是一项让人非常兴奋的技术,相信它会变的越来越流行。我对这项技术非常的欣赏——尽管我们最近把Targeter App从NodeJS迁移到了Ruby on Rails。
我是NodeJs的大粉丝,认为这是一项让人非常兴奋的技术,相信它会变的越来越流行。我对这项技术非常的欣赏——尽管我们最近把Targeter App从NodeJS迁移到了Ruby on Rails。
我们当时使用NodeJS开发 它的原因很简单。我有一个程序包,能很快的将我们的应用弄上线(我们花了54小时做这个事情),相比起Ruby,我更常使用的是 JavaScript。因为我们的技术架构牵涉到MongoDB,我的这些特长只有在NodeJS环境里才会有意义。然而,随着应用规模的增 长,我认识到,选择NodeJS来实现这个应用是个错误的选择。下面让我来概述一下其中的原因。
NodeJS很适合做那些有大 量短生命期请求的应用。对于传统的CRUD应用,它也很好,但不是非常的理 想。在PHP,Ruby,Python语言里都有很成熟、优化的很好的框架来处理这种应用。NodeJS里的所有东西都异步执行的理念对于 CRUD应用来说没有任何效果。其它语言里的流行的框架能提供非常好的缓存技术,你所有的需求都能满足,包括异步执行。
NodeJS是一种非常年 轻的技术框架,它的周边程序库都不是很成熟。我说这些并没有任何对那些代码捐赠者冒犯的意思,他们很优秀,开发出来很 多优秀的程序库。然而,大部分程序库需要改进,而NodeJS的这种快速成长的环境意味着每一版升级中都带有大量的变化;当你使用一种前沿技 术时,你十分有必要尽快的紧跟最新的版本。这给创业型的企业带来了很多的麻烦。
另外一个原因是关于测 试。NodeJS里的测试框架还不错,但跟Django或RoR平台上的相比还是差一些。对于一个每天都有大量的代码 提交、并且在一两天内就要发布的应用来说,程序不能出问题是至关重要的,否则你为此辛苦的努力变得得不偿失。没有人愿意花一天的时间改一些弱 智的bug。
最后一点,我们需要的是一种能缓 存一切的东西,并且要尽快的实现。尽管我们的应用在增长,每秒钟有上万次的hits,但绝不会出现很大量的访问请求; 这不是一个聊天程序!主程序最多时也就达到1000RPS,这样的负载对于Ruby on Rails和Nginx来说算不了什么。
如果你现在还在读这篇文章,那 你已经看到了我所有要说的了,你也许非常坚持的想知道我们的应用什么地方还在使用NodeJS。是这样的,我们的应用由两部分组成。一是界 面,用户看到的这部分,二是负责报表管理的部分,以及做日志的功能。后者是NodeJS的一个最佳使用场景,存在有大量的短周期的请求。这部 分的动作需要尽快的执行完成,甚至要在我们的数据推送还没有完成之前。这很重要,当请求执行还未结束,浏览器继续等待响应结束,这会影响用户 使用体验。NodeJS的异步特性救了我们。数据要么被存入数据库,要么被处理掉,当请求一旦执行完成,浏览器就可以开始做其它重要的事情 了。
Ruby - Convert json to hash and visa versa
Hash to Json: your_hash.to_json
Json to Hash: JSON.parse( your_json )
Json to Hash: JSON.parse( your_json )
Scaling PostgreSQL at Braintree: Four Years of Evolution
reference:https://www.braintreepayments.com/braintrust/scaling-postgresql-at-braintree-four-years-of-evolution
Scaling PostgreSQL at Braintree: Four Years of Evolution
::Base around_filter :activate_shard def activate_shard(&block) merchant = Merchant.find_by_public_id(params[:merchant_id]) DataFabric.activate_shard(:shard => merchant.shard, &block) end end
Scaling PostgreSQL at Braintree: Four Years of Evolution
We love PostgreSQL at Braintree. Although we use many different data stores (such as Riak,MongoDB, Redis, and Memcached), most of our core data is stored in PostgreSQL. It's not as sexy as the new NoSQL databases, but PostgreSQL is consistent and incredibly reliable, two properties we value when storing payment information.
We also love the ad-hoc querying that we get from a relational database. For example, if our traffic looks fishy, we can answer questions like "What is the percentage of Visa declines coming from Europe?" without having to pre-compute views or write complex map/reduce queries.
Our PostgreSQL setup has changed a lot over the last few years. In this post, I'm going to walk you through the evolution of how we host and use PostgreSQL. We've had a lot of help along the way from the very knowledgeable people at Command Prompt.
2008: The beginning
Like most Ruby on Rails apps in 2008, our gateway started out on MySQL. We ran a couple of app servers and two database servers replicated using DRBD. DRBD uses block level replication to mirror partitions between servers. This setup was fine at first, but as our traffic started growing, we began to see problems.
2010: The problems with MySQL
The biggest problem we faced was that schema migrations on large tables took a long time with MySQL. As our dataset grew, our deploys started taking longer and longer. We were iterating quickly, and our schema was evolving. We couldn't keep affording to take downtime while we upgraded or even added a new index to a large table.
We explored various options with MySQL (such as oak-online-alter-table), but decided that we would rather move to a database that supported it directly. We were also starting to see deadlock issues with MySQL, which were on operations we felt shouldn't deadlock. PostgreSQL solved this problem as well.
We migrated from MySQL to PostgreSQL in the fall of 2010. You can read more about the migration on the slides from my PgEast talk. PostgreSQL 9.0 was recently released, but we chose to go with version 8.4 since it had been out longer and was more well known.
2010 - 2011: Initial PostgreSQL
We ran PostgreSQL on modest hardware, and we kept DRBD for replication. This worked fine at first, but as our traffic continued to grow, we needed some upgrades. Unlike most applications, we are much heavier on writes than reads. For every credit card that we charge, we store a lot of data (such as customer information, raw responses from the processing networks, and table audits).
Over the next year, we performed the following upgrades:
- Tweaked our configs around checkpoints, shared buffers, work_mem and more (this is a great start: Tuning Your PostgreSQL Server)
- Moved the Write Ahead Log (WAL) to its own partition (so fsyncs of the WAL don't flush all of the dirty data files)
- Moved the WAL to its own pair of disks (so the sequential writes of the WAL are not slowed down by the random read/write of the data files)
- Added more RAM
- Moved to better servers (24 cores, 16 disks, even more RAM)
- Added more RAM again (kept adding to keep the working set in RAM)
Fall 2011: Sharding
These incremental improvements worked great for a long time, and our database was able to keep up with our ever increasing volume. In the summer of 2011, we started to feel like our traffic was going to outgrow a single server. We could keep buying better hardware, but we knew there was a limit.
We talked about a lot of different solutions, and in the end, we decided to horizontally shard our database by merchant. A merchant's traffic would all live on one shard to make querying easier, but different merchants would live on different shards.
We used data_fabric to introduce sharding into our Rails app. data_fabric lets you specify which models are sharded, and gives you methods for activating a specific shard. In conjunction with data_fabric, we also wrote a fair amount of custom code for sharding. We sharded every table except for a handful of global tables, such as merchants and users. Since almost every URL has the merchant id in it, we were able to activate shards in application_controller.rb for 99% of our traffic with code that looked roughly like:
class ApplicationController ActionController
Making our code work with sharding was only half the battle. We still had to migrate merchants to a different shard (without downtime). We did this with londiste, a statement-based replication tool. We set up the new database servers and used londiste to mirror the entire database between the current cluster (which we renamed to shard 0) and the new cluster (shard 1).
Then, we paused traffic[1], stopped replication, updated the shard column in the global database, and resumed traffic. The whole process was automated using capistrano. At this point, some requests went to the new database servers, and some to the old. Once we were sure everything was working, we removed the shard 0 data from shard 1 and vice versa.
The final cutover was completed in the fall of 2011.
Spring 2012: DRBD Problems
Sharding took care of our performance problems, but in the spring of 2012, we started running into issues with our DRBD replication:
- DRBD made replicating between two servers very easy, but more than two required complex stacked resources that were harder to orchestrate. It also required more moving pieces, likeDRBD Proxy to prevent blocking writes between data centers.
- DRBD is block level replication, so the filesystem is shared between servers. This means it can never be unmounted and checked (fsck) without taking downtime. We become increasingly concerned that filesystem corruption would go unnoticed and corrupt all servers in the cluster.
- The filesystem can only be mounted on the primary server, so the standby servers sit idle. It is not possible to run read-only queries on them.
- Failover required unmounting and remounting filesystems, so it was slower than desired. Also, since the filesystem was unmounted on the target server, once mounted, the filesystem cache was empty. This meant that our backup PostgreSQL was slow after failover, and we would see slow requests and sometimes timeouts.
- We saw a couple of issues in our sandbox environment where DRBD issues on the secondary prevented writes on the primary node. Thankfully, these never occurred in production, but we had a lot of trouble tracking down the issue.
- We were still using manual failover because we were scared of the horror stories withPacemaker and DRBD causing split brain scenarios and data corruption. We wanted to get to automated failover, however.
- DRBD required a kernel module, so we had to build and test a new module every time we upgraded the kernel.
- One upgrade of DRBD caused a huge degradation of write performance . Thankfully, we discovered the issue in our test environment, but it was another reason to be wary of kernel level replication.
Given all of these concerns, we decided to leave DRBD replication and move to PostgreSQL streaming replication (which was new in PostgreSQL 9). We felt like it was a better fit for what we wanted to do. We could replicate to many servers easily, standby servers were queryable letting us offload some expensive queries, and failover was very quick.
We made the switch during the summer of 2012.
Summer 2012: PostgreSQL 9.1
We updated our code to support PostgreSQL 9.1 (which involved very few code changes). Along with the upgrade, we wanted to move to fully automated failover. We decided to use Pacemaker and these great open source scripts for managing PostgreSQL streaming replication: https://github.com/t-matsuo/resource-agents/wiki. These scripts handle promotion, moving the database IPs, and even switching from sync to async mode if there are no more standby servers.
We set up our new database clusters (one per shard). We used two servers per datacenter, with synchronous replication within the datacenter and asynchronous replication between our datacenters. We configured Pacemaker and had the clusters ready to go (but empty). We performed extensive testing on this setup to fully understand the failover scenarios and exactly how Pacemaker would react.
We used londiste again to copy the data. Once the clusters were up to date, we did a similar cutover: we paused traffic, stopped londiste, updated our database.yml, and then resumed traffic. We did this one shard at a time, and the entire procedure was automated with capistrano. Again, we took no downtime.
Fall 2012: Today
Today, we're in a good state with PostgreSQL. We have fully automated failover between servers (within a datacenter). Our cross datacenter failover is still manual since we want to be sure before we give up on an entire datacenter. We have automated capistrano tasks to orchestrate controlled failover using Pacemaker and traffic pausing. This means we can perform database maintenance with zero downtime.
One of our big lessons learned is that we need to continually invest in our PostgreSQL setup. We're always watching our PostgreSQL performance and making adjustments where needed (new indexes, restructuring our data, config tuning, etc). Since our traffic continues to grow and we record more and more data, we know that our PostgreSQL setup will continue to evolve over the coming years.
[1] For more info on how we pause traffic, check out How We Moved Our Data Center 25 Miles Without Downtime and High Availability at Braintree
Subscribe to:
Posts (Atom)